
When dealing with a file that has a large number of entries, sorting the contents in a certain order can make things so much easier. In Linux, the sort command, which employs the merge sort algorithm, is used for this purpose.
The sort command compares all lines from the given files and sorts them in the specified order based on the sort keys. The -k option, in particular, is used to sort on a certain column.
In conjunction with the -k option, you’ll also need to know about other options like -n or -r to efficiently sort by column. We’ve detailed these and other related topics in the sections below.
Sort By Column
The base syntax for the sort command is sort <option> <file>. To apply this, let’s start with an example. Let’s say we have a contacts.txt file with the following entries:
Emma Smith US 51
Edward Dyer UK 19
Natalie Russell Canada 22
Mathew Roberts Germany 21
Ruth Abraham Australia 44
Joseph Smith France 25Just using the sort contacts command would sort the entries in alphabetical order based on the first column. To sort by another specific column, or in another order, you’ll have to use various options, which we’ve listed below.
Option -k
As stated, the --key, or -k option is used to sort on a specific column or field. For instance, in our example, if you wanted to sort by nationality, you’d use the following command to sort on the third column:sort -k3 contacts

This command will take all fields from 3 to the end of the line into account. Alternatively, if you used sort -k3,4 contacts, this would specify to use the fields from #3 to #4, i.e., the third to fourth fields.
If you were trying to sort by surnames in the second column, there are two scenarios to consider. As there are identical entries (Smith), sort will use the next entry for the tiebreaker. I.e., in the case of the two smiths, France would be sorted above US.
But what if you needed to sort by surname, name, and only then nationality? In such cases, you can manipulate the sort order by specifying keys multiple times as such:sort -k2,2 -k1,1 contacts

Option -n
If you use the commands shown above to sort by age on the fourth column, the results would seem inaccurate. As sort takes a lexicographic approach, fiftyone would rank above nineteen.
To sort a column by numbers, you have to instead specify the -n option as such:sort -n -k4 contacts

Option -r
If you were trying to sort entries in reverse order, you would use the -r option. This is true for both alphabetical and numeric values, as shown below:sort -r -k1,1 contacts
sort -r -k3,4 contacts

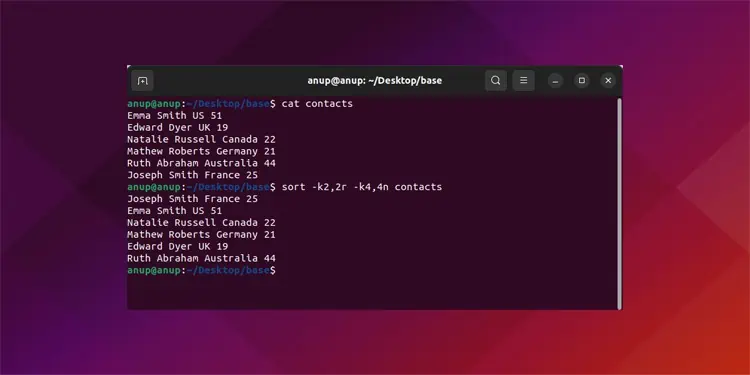
By combining the basic options we’ve listed so far, you could perform complex sorting operations like reverse sorting on the second column and numerically sorting on the fourth column at once:sort -k2,2r -k4,4n contacts

Option -t
A blank space is the default field separator, i.e., delimiter with sort. But CSV files use commas (,) to separate values. Depending on what delimiter is used, you can specify it using the -t option. For instance, if : is the delimiter, you would specify it as such:sort -t ':' -k2 contact

Option -o
You can use the -o option to save the sorted output into a specified file as such:sort -k2 contacts -o sortedcontacts

Additional Options
The options detailed above are the most commonly used ones. But sort has countless other flags that could be useful in niche scenarios like -b to ignore blank spaces at the start of the file, -M to sort the contents as per the calendar month, or -c to check if data is already sorted. As there are too many to list here, we recommend referring to the sort man page for the full list of such options.